MIT Study Discovers Labelling Errors in AI Training Datasets
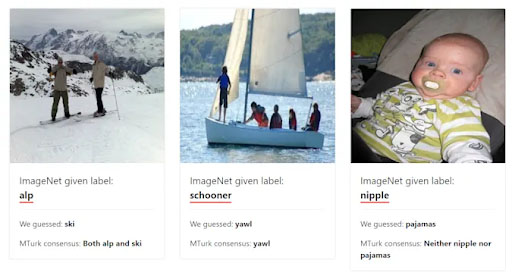
A team of MIT computer scientists examined ten of the most used datasets for testing machine learning systems. The researchers found that around 3.4 percent of the data that is used for such things was inaccurate or simply mislabeled. This can cause problems in AI systems that use these datasets.
The general rule is: Garage in, garbage out.
Each of these ten datasets have each been cited more than 100,000 times. This includes text-based ones models from newsgroups, IMDb, and even Amazon. For example, a small percentage of Amazon product reviews were being mislabeled as positive when they were negative reviews.
Some of these are image-based errors. This manifests itself as mixing up animal species. Other errors were smaller, such as detecting the subject of a photo to be a water bottle rather than the bike that it was attached to.
One of the datasets that has problems is related to YouTube videos. There was a clip of someone talking to the camera for three and a half minutes that was for some reason labeled as a church bell. There was a less inaccurate error, though. The AI datasets had classified a Bruce Springsteen performance as an orchestra.
The team was able to detect the errors using a framework called ‘confident learning.’ This framework examines datasets for irrelevant data, which is known as label noise. The researchers were able to validate the possible mistakes using Amazon Mechanical Turk. They found that about 54 percent of the data was incorrectly labeled.




{kind=link}